Microservices, lessons learned
A few weeks back, I read Andrei Taranchenkos article Death by a thousand microservices and Justin Etheredges’ Gasp! You Might Not Need Microservices, which are both excellent articles. I have been wanting to write this article for a while now, and after reading those two I decided it was finally time, but I still doubted if the world really needed another microservice critical article. A few days ago, when reading something on Reddit, I stumbled on this guy arguing that they would soon migrate to microservices. I almost wrote a comment in CAPS, but it was off-topic, and hey - he might have a real reason to actually migrate. But it seems that the world still needs microservice critical articles.
I was formerly the co-founder and CTO of TestaViva, where I decided to move from a monolith to microservices five years back. This article will be a set of practical pros and cons for choosing microservices, based on my experiences.
This article will discuss the following aspects:
- Why did we move to microservices
- Things I liked about microservices
- Things I thought we would get, but that we didn’t get
- Things I thought we would like, but that we really didn’t need
- Challenges, downsides, and straight-up problems we faced
Let’s go :)
Why did we move to microservices
At TestaViva we were not flush with money, and we didn’t board the microservice hype train just because of that hype nor because anyone telling us we should. I made that decision because I wrongfully believed it would solve some real-life problems. Microservices seemed to bring all the solutions, with a minimum of downsides. When reading the articles above, especially Etheredges, it seems like a classic example of wanting to move fast but ending up moving just as slow, or maybe even slower, than before.
The problems we faced were:
- Slow-running test suite.
- An out-of-date framework
- Needlessly complex code
Besides solving these problems, I figured the advantages we would gain from microservices would be:
- Motivated developers
- Service scalability
- Easy separation of code ownership
The strategy was simple; every time we added features or refactored code in the monolith, we would branch out and create a new microservice. Basically, I introduced a code freeze in the monolith. This was back in 2018, and we were in no immediate time rush. The only real deadline we had was the end of life for our framework. That was three years into the future and that seemed like light-years away.
Things I liked about microservices.
There were things that I liked very much about the shift to microservices, besides the fact it felt extremely cool to brand TestaViva as working with microservices. Unfortunately these things wasn’t related to the technical aspects of microservices.
Recruitment
Back in 2018, we were running a Symfony 3.4 monolith. If you have been part of the PHP community for the past years you probably have heard of Symfony, but you probably also know that it lost the race to Laravel. To back this statement, Laravel currently has 115% more stars on GitHub than Symfony.
The past year the market has definitely changed from an employee’s market to an employer’s market. I wouldn’t say that it was impossible to find Symfony developers back then, but it was very clear that Laravel openings just attracted more talent (but also more “Laravel developers”, which I don’t think you always want to attract, but that’s another story).
Making the move to a microservice setup, made us brand ourselves as a Laravel product and team. Sure, you were told that you’d probably have to maintain some Symfony services but eyeing the chance of rolling your own Laravel services, worked well as a selling point.
Furthermore, branding TestaViva as working with microservices also added value. I’ve actually had one developer specifically joining the team to learn more about microservices and work with the architecture.
Software engineer responsibility and progression
Being a start-up often makes it difficult to compete with high salaries, so you need to attract and motivate talent by other means. There are many ways to achieve this, but giving engineers responsibility and enabling them to try out new technologies will often work towards that.
Microservices make it very easy to do both since you often find yourself rolling new services, which brings opportunities to try new frameworks (depending on your developer strategy of course). I’ve literally had more than a few developers telling me that they loved their work due to them building new services from scratch and having a big impact on the layout and architecture of that new service.
Things I thought we would get, but that we didn’t get.
Unfulfilled dreams 💔
Staying up to date with the latest security updates
Our monolith was getting old fast, and years of neglecting updates resulted in having to update two major versions. We tried a few times, which basically resulted in too many failing tests, and really, we didn’t want to lose focus on building our product.
When I left TestaViva the monolith, although smaller than in its prime, is still going strong. And unless the new CTO can do magic (he is a talented guy, so who knows) it will continue to go strong, for a looong time.
With microservices, instead of having to update one framework, the tech team now had to maintain and update +20 microservices. The codebases and test suites are smaller of course, but do it 20 times, and my bet is that no time is really saved in the end.
Less complex code
The original core of the monolith was developed by a Polish software team, and although they did a good job, they also did some over-engineering in parts of the monolith.
By separating into microservices we would get a good chance to refactor the complicated parts. I personally put my best engineering talents into building our very first microservice (well, second actually, the first one being a microservice that would keep track of the versions of our future microservices). As someone passionate about automated testing, I implemented the Humble Object design pattern for that microservice.
This served us well for a while until feature creep crept in and too many different developers made the pattern implementation fall apart. Honestly, now that microservice is just one big mess. Complex, and over-engineered.
It would seem that microservices can’t do magic, and solve complexity 🪄
Things I thought we would like, but that we really didn’t need.
Spending more time on thinking it through, would probably have surfaced these findings before starting the implementation. Nevertheless, it would seem that we were not the only ones thinking we would benefit from some of the cool stuff microservices provides.
Service scalability
Don’t solve problems you don’t have.
Yes, we could scale independent parts of our platform, but not once in my five years with microservices did we have to do that.
In TestaViva’s case, we did have one relevant use case. We had a partner who inside a WebView in their native app integrated a small, encapsulated part of TestaViva. Originally, we had built that feature in the monolith, meaning it would have to boot a lot of unnecessary stuff.
Moving to microservices, we decided to put that feature into its own microservice. This did decrease the time to first paint from around 1200ms to 600ms, making the overall feel of the implementation more respondent and a lot better in general. But running a monolith do not equal not separating logic and concerns by running multiple services.
The next time I’m CTO for any product, we will keep our monolith, but still roll separate services, when use-cases like this arises.
Easy separation of code ownership
Having repositories that contain one service, makes it easy to assign the responsibility for that service to specific teams. But truth be told, with small teams and relatively small codebases like TestaViva, I’m unsure about the benefits you get from separating the codebase?
You do gain quality and velocity by having the authors maintain it, no doubt. But with small teams, I’m afraid that you also end up blocking each other’s progress too often, which can be much worse than moving slow. It will also be an easy excuse for not fixing stuff. (“I would do task X, but I’m waiting on team Y”).
Challenges, downsides, and straight-up problems we faced
Unfortunately, it turned out that microservices brought a lot more challenges and straight-up problems than benefits. I’m sure that more talented CTOs, more talented people, and better organized teams out there really love microservices and their microservices implementation, but it was not a perfect fit, not even a good fit, for us.
Integrations tests - LOL
At TestaViva (and its predecessor, Sikkerarv) we have always enjoyed the benefits of a solid CI workflow and day-to-day releases. When I left TestaViva, that was still the case, but with more pain and suffering than we used to have.
The integration tests became more and more flaky, primarily because we did not solve the problem of test dependencies that microservices brings along. We also started purposely skipping some would-have-brought-value integration tests, just because it was near impossible to write them. Flaky tests and skipping tests are the direct route to hell a less stable product, and the direct route to me losing sleep.
It’s a little difficult to explain, and if you don’t care about the technicalities and just trust my written word, you can safely skip to the next part.
An API should be stable, and in most cases our API was stable. Since our API was not consumed by any external partners, it was sometimes easier to cut corners and alter them anyway.
Even if no APIs were altered, bugs were sometimes introduced, which didn’t get picked up by the test suite in the microservice itself, and therefore made their way into production.
Both cases resulted in other microservices that depended on now missing API endpoints or the now faulty microservice starting to fail their test suites. Or Sentry would start picking up errors. Or our users would. The worst scenario was the last of course (our users suffering) but in all three scenarios it was too late; the bug was in production.
There are ways to fix this, I’m aware, but we just couldn’t find the time to implement that in our workflow, and we were already paying way too much for our CI runner. To mitigate this just a bit, we introduced nightly runs of the test suites of all our microservices. But that’s really like popping a painkiller or peeing in your pants to stay warm.
It’s just too complicated.
Valuable time wasted on DevOps
I personally ended up writing a whole DevOps service in bash and Python that did nothing but assist our developers in their day-to-day work with the microservices. It brought a lot of convenience features, making their life better, but only because their life was bad due to the complexity added by the microservice architecture in the first place. It’s not a paradox, it’s just plain stupid.
To make matters worse, in my role as CTO I was supposed to:
- Guide the team and improve our much-valued talent.
- Dive into product development and make all my LegalTech experience matter.
- Create state-of-the-art legal tech products.
Of course I did spend my time doing that, but too much time went into maintaining a DevOps repository with helper tools we didn’t need in the first place. (Nothing doesn’t come from something – it did raise my level in Python, of which I’m very fond).
Working on multi-service features and the configuration hell
Working on a feature that involves only one microservice is easy (duh). Working with two is also alright. But when you need to balance 3+ microservices, things start getting messy.
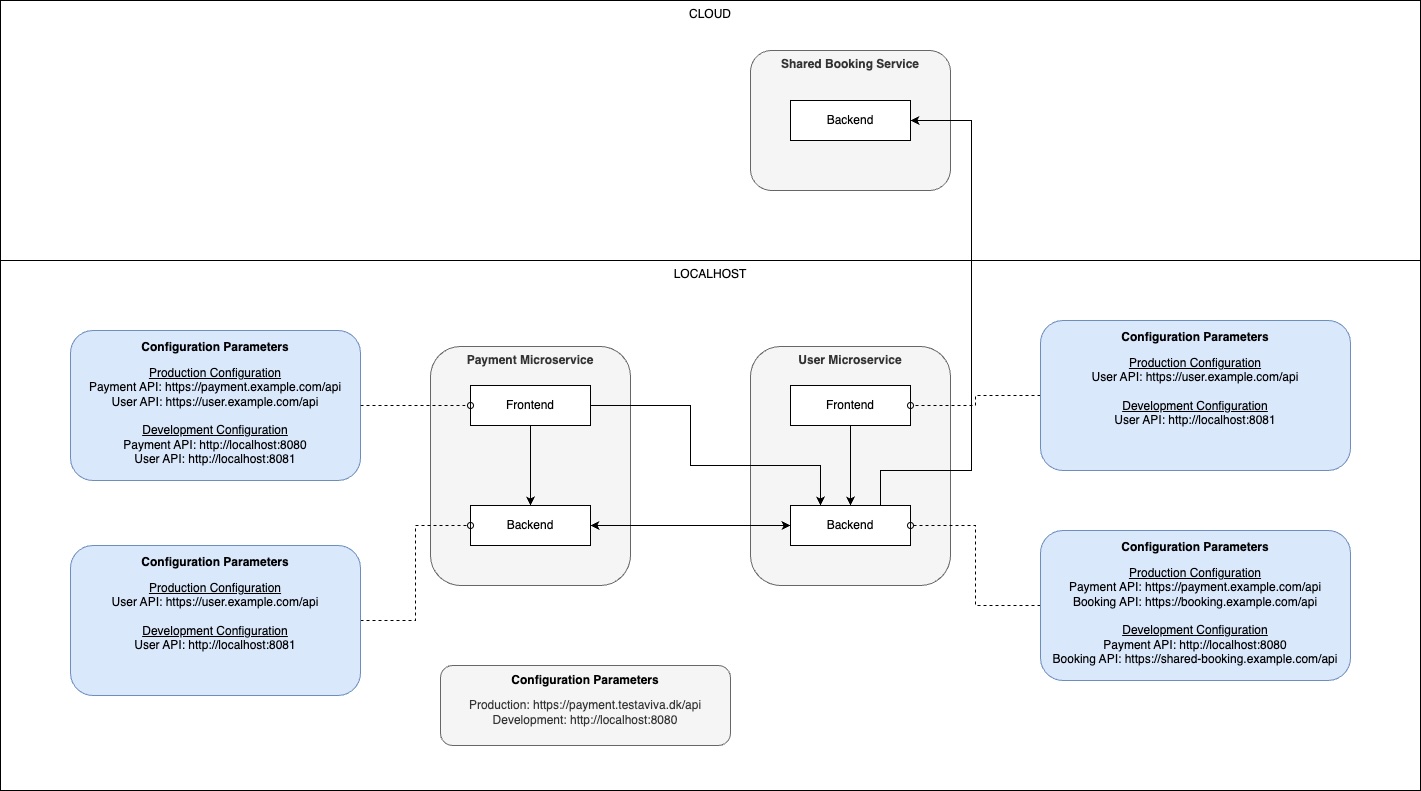
By nature, they all have their own databases, and some of them also have their own frontends. So, you would need to make sure the configuration for the JavaScript compiler was linked correctly and all the environment variables configured with all the right links between the microservices. And there could be multiple links between microservices, private and public.
Too often you would end up being puzzled about why it would seem that something was off, even though things were working. This was almost always due to the fact that you missed one of these links and requests was either going nowhere or going to one of our shared development services (making it work, just not the way you would expect it to).
When you became more traversed in our setup, the occurrences of faults related to misconfiguration became rare, but it would still happen, and for new developers (even senior ones) it was a steep learning curve.
Maintaining boilerplate code
When you have a monolith and maybe a few other services, doing scaffolding is not something you need to do often. When you are migrating from a monolith to microservices, and are trying to microservicefy everything, maintaining boilerplate code suddenly becomes a recurring task.
Taranchenko has a pretty good list of things you need to do every time you roll a new microservice, and our list was almost a carbon copy of that list.
Working smarter, not harder, made us set up boilerplate repositories with prebuilt services we needed (Frontend, Symfony, Laravel).
Very nice, except every time you rolled a new service, you had to:
- Get rid of the stuff you didn’t need in your service.
- Update all dependencies to the latest versions.
- Update all dependencies in the boilerplate itself, to decrease the chance by roughly 1% that the next developer would need to update the dependencies.
Hard work.
It was my decision, and I was wrong
In the end, it turned out that microservices only solved one-half of our original problems (slow-running tests) and only added one of the benefits (motivated developers). The other problems were either not solved, or just replaced by the same problems with a different flavor. Adding to that, a lot of unexpected challenges and problems were also brought to the table.
So yeah, I was wrong. If I were to go back, I would stop myself from making that decision. I defended my decision for a long time, and not because of pride, but because I really believed that we would harvest the benefits in the long run, but I’m of another belief this day.
At least I know now that my next product will be a monorepo with a minimum of services, probably, hopefully, only a backend and a frontend services, and I’ll be happy about it - also when the next microservice hype train arrives in 10-20 years I’ll make sure to not board it (when you stick around long enough, you realize that everything is just a recursion).
Post Scriptum: The slow-running tests
At the time we started our migration to microservices, our test suite had a runtime of approximately 45 minutes. It was beginning to make our CI workflow more painful. Since the CI workflow would need to run twice for a production build, correcting bugs would require at least two hours of waiting. That was really frustrating for both the business and the developers (me included).
Turned out it wasn’t the monolith that was the cause of the problems, it was the design of our test suite.
A well-designed test suite looks like this:
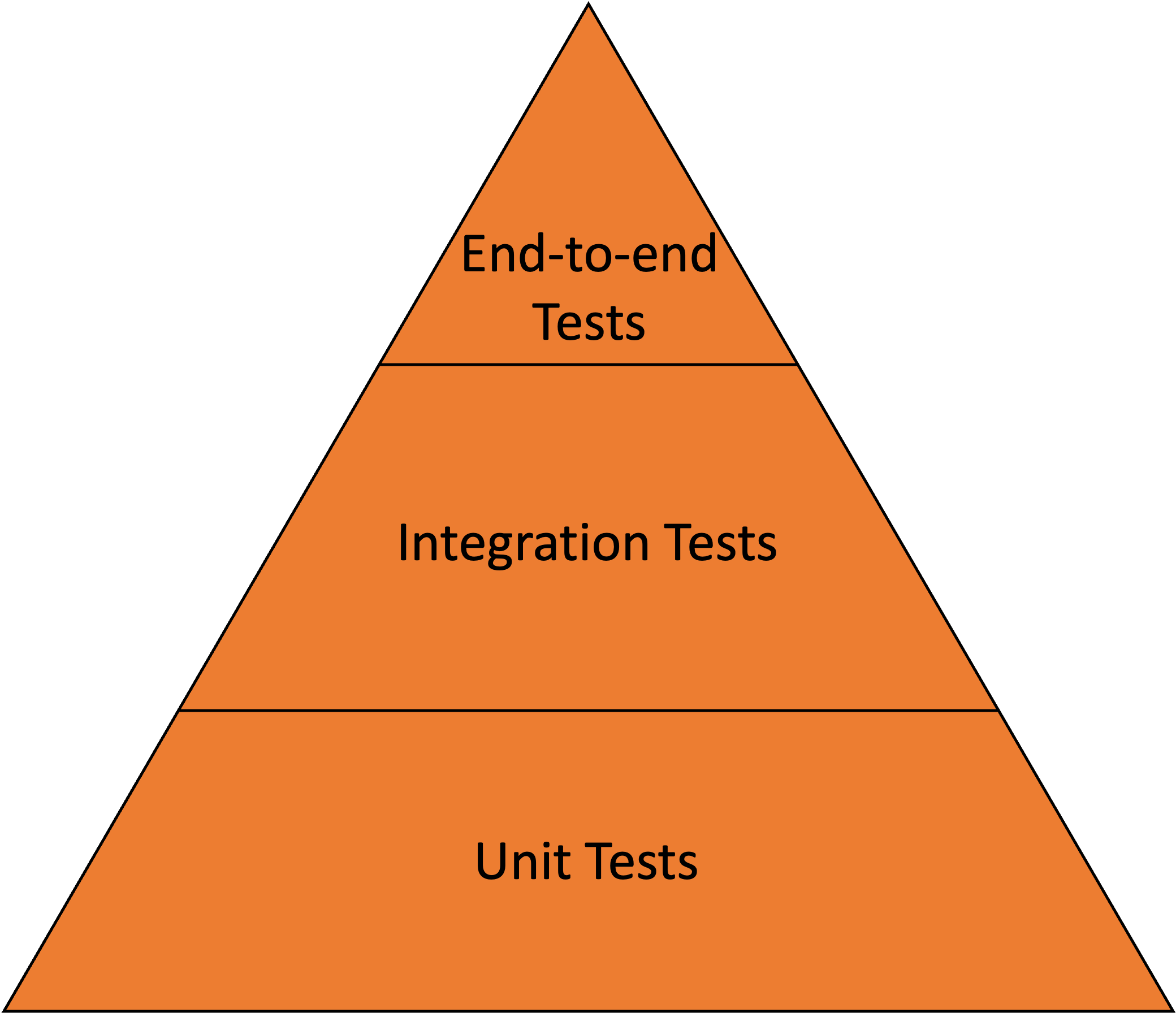
Our test suite looked like this:
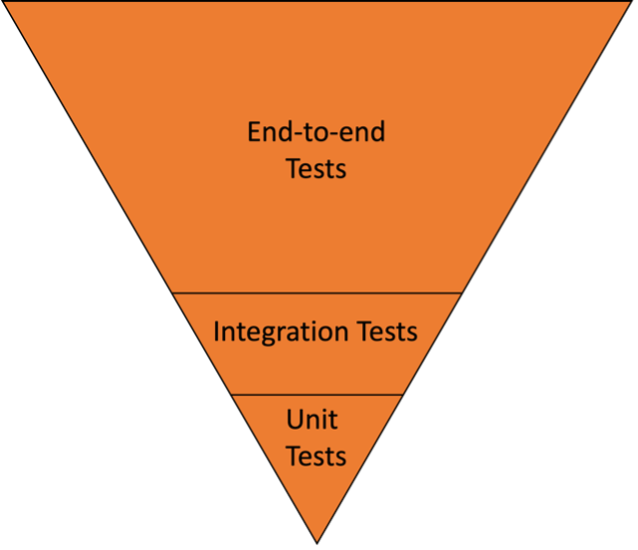
And how did this happen? Again, ignorance.
In 2015 when the Polish team built our product, they asked me if it was okay for them to write Behat (end-to-end) tests instead of PHPUnit tests. We argued back and forth, but in the end the winning argument was that they would move faster (and thereby cheaper) with Behat instead of PHPUnit. I was young(er) and inexperienced in software testing. Today I would never have allowed it, but instead bought them a software testing course.
The end
If no one ever makes it this far, at least I had a lot of fun writing it :)